深度学习

深度学习
Nuyoah深度学习
基本流程:
- 数据的获取
- 特征工程 最核心
- 建立模型
- 评估与应用
特征工程的作用:
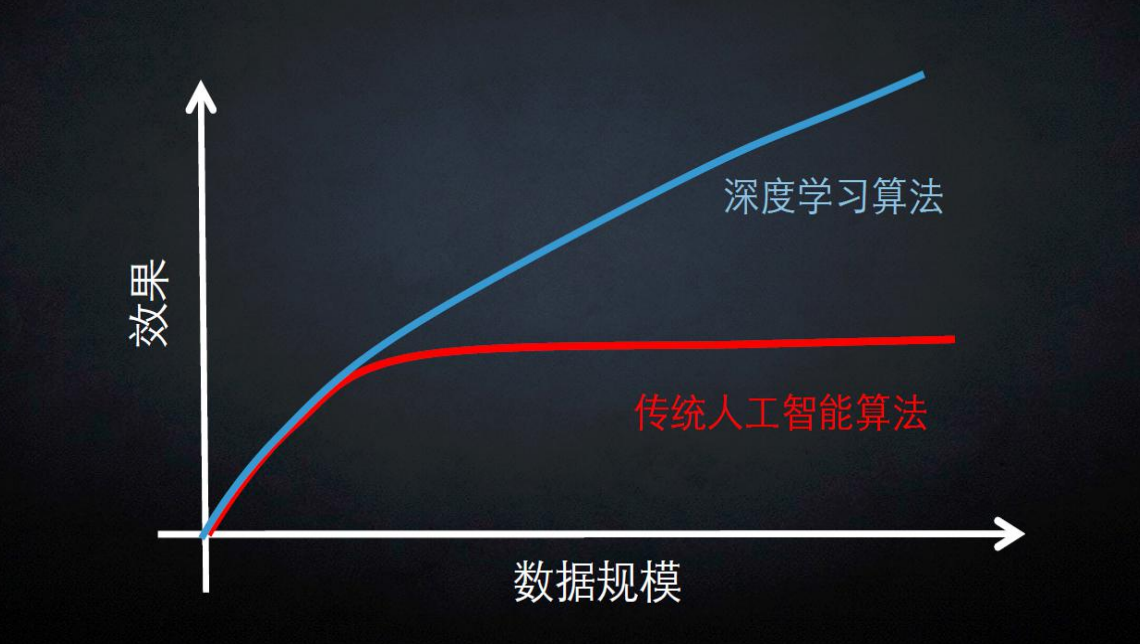
- 数据特征决定了模型的上限
- 预处理和特征提取是最核心的
- 算法和参数的选择,只是为了逼近这个上限

特征如何提取:

传统特征提取方法:

图像分类
给定一张图片,计算机能够自动的识别该图像中的某一部分属于那个类别
图像的表示 :计算机眼中的图像是一串串数字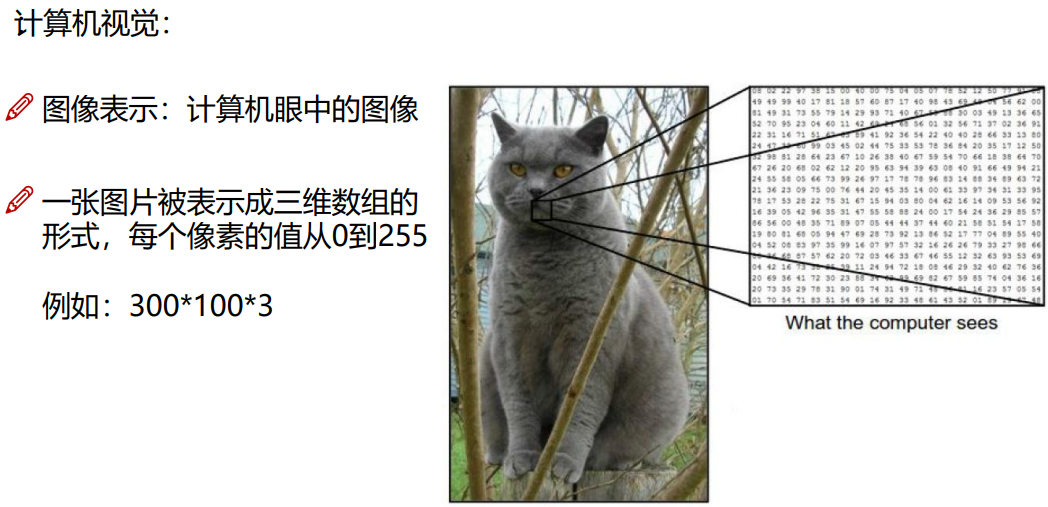
计算机视觉-图像分类面临的挑战:
- 照射角度
- 形状改变
- 部分遮蔽
- 背景混入
机器学习常规套路:
- 收集数据并给定标签
- 训练一个分类器
- 测试,评估
k临近算法:
- 计算已知类别数据集中的点与当前点的距离
- 按照距离依次排序
- 选取与当前点距离最小的K个点
- 确定前K个点所在类别的出现概率
- 返回前K个点出现频率最高的类别作为当前点预测分类
- 缺点:
- 被分类的对象会受背景主导,不能够聚焦到我们所关注的主体上
神经网络基础
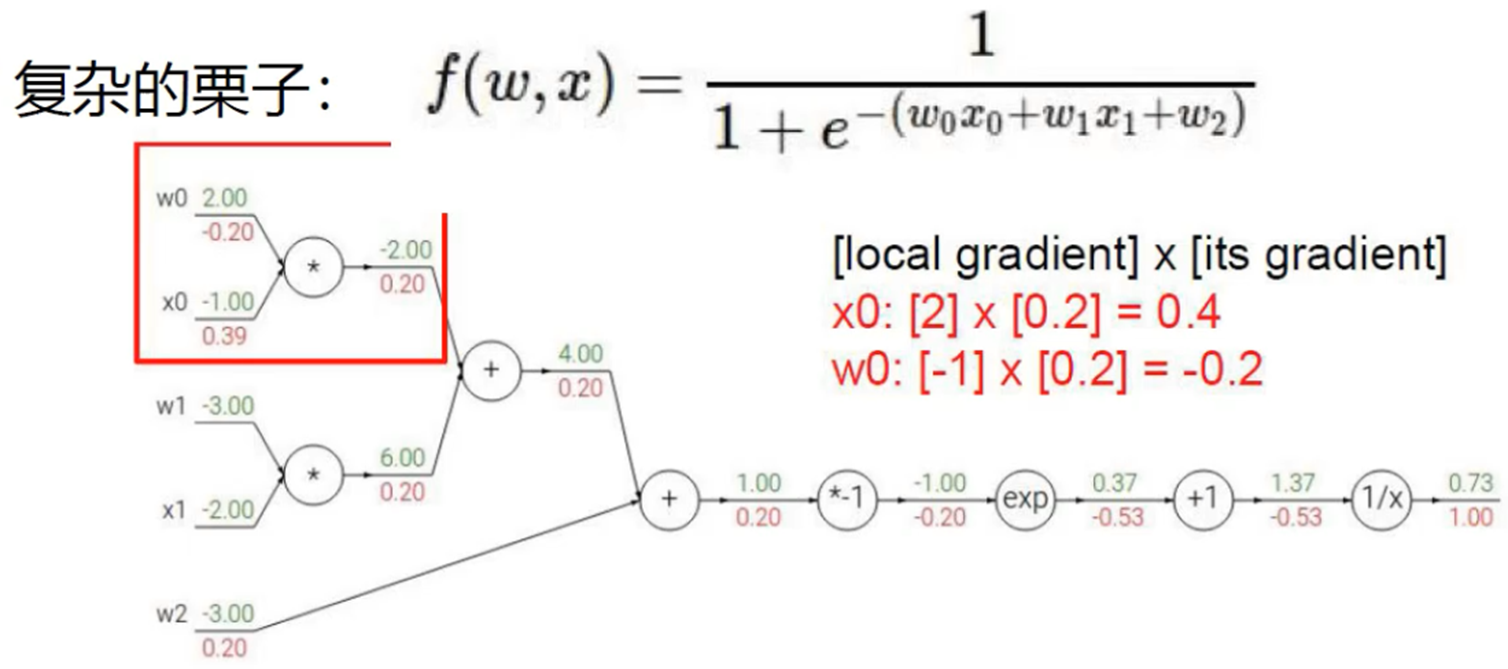
f() 表示一个函数, W表示每个类别的权重, x 表示目标图像的所有像素点, b表示对每个类别进行微调
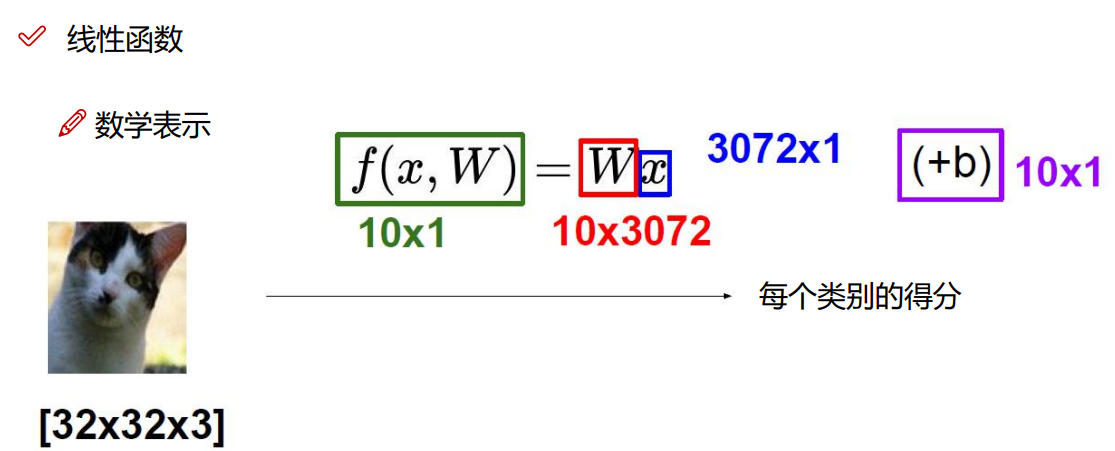
运算结果:

从图中可以看出,猫被分为了狗类,导致这种情况的主要原因是:权重参数矩阵W的不合理,所以神经网络主要是在不断的更新权重矩阵 ,初始的时候我们可以随机初始化权重矩阵W,然后通过不断的优化,更新,得出最优矩阵
损失函数


正则化惩罚项:是为了解决权重参数带来的影响
梯度运算
通过这个方法最终还是得出的得分值,但是我们想要一个概率值,如何把得分值转变为概率值那?
使用Softmax分类器
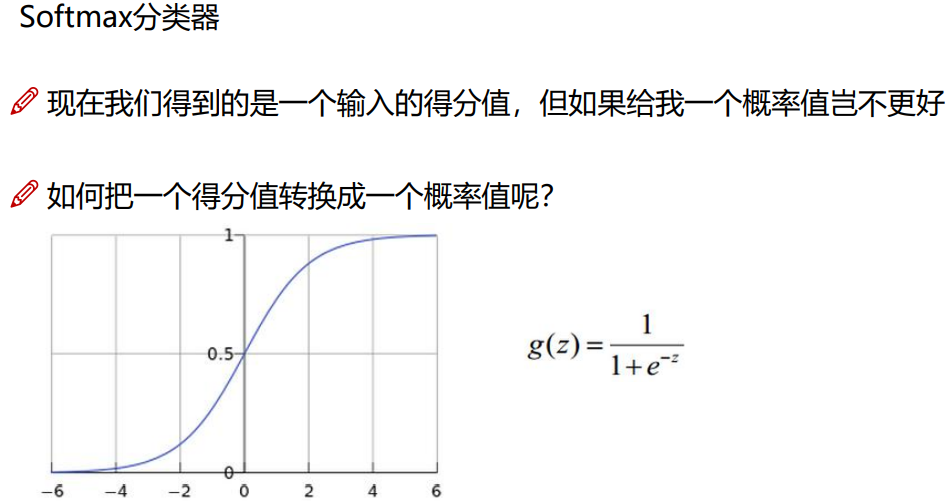

向前传播得到得分值

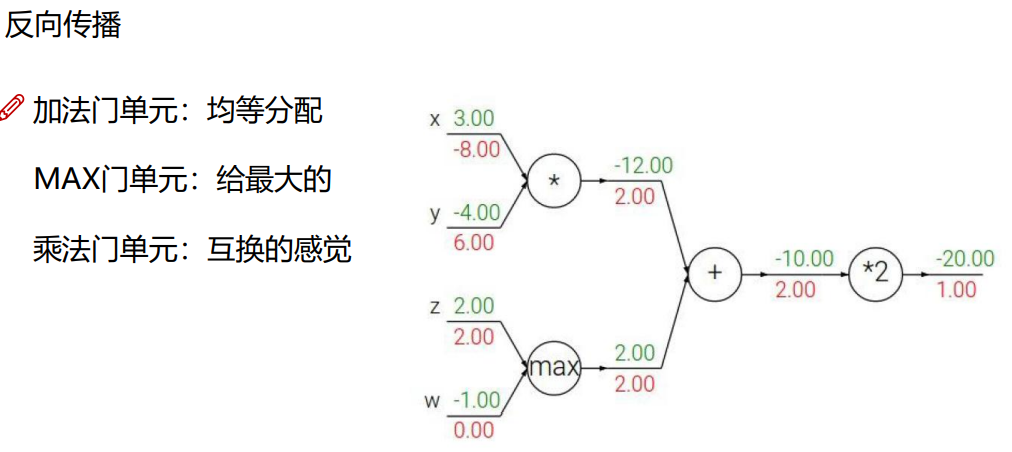
梯度下降
引入:当我们得到了一个目标函数后,如何进行求解?
直接求解?(并不一定可解,线性回归可以当做是一个特例)
常规套路:机器学习的套路就是我交给机器一堆数据,然后告诉它什么样的学习方式是对的(目标函数),然后让它朝着这个方向去做
如何优化:一口吃不成个胖子,我们要静悄悄的一步步的完成迭代(每次优化一点点,累积起来就是个大成绩了)
神经网络
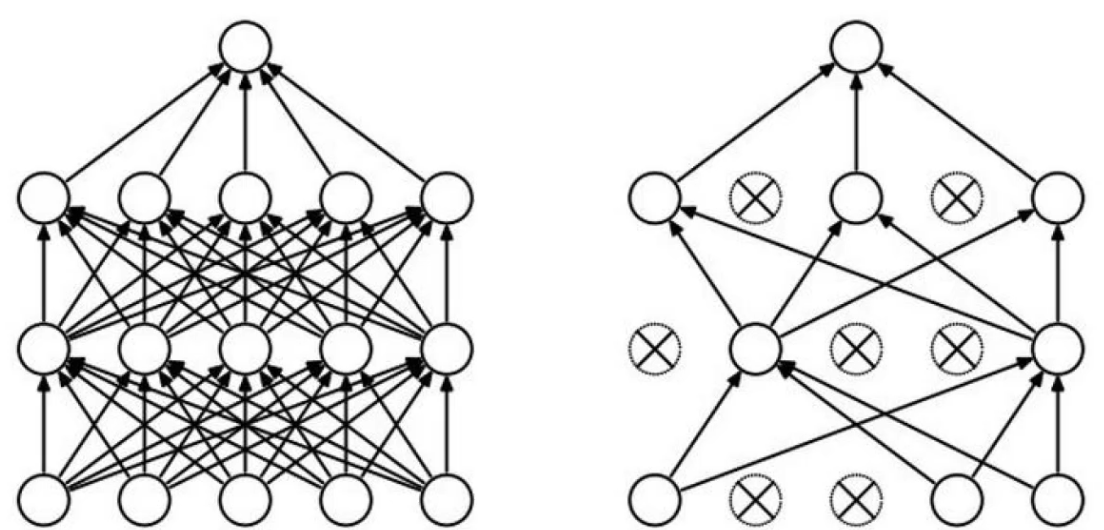
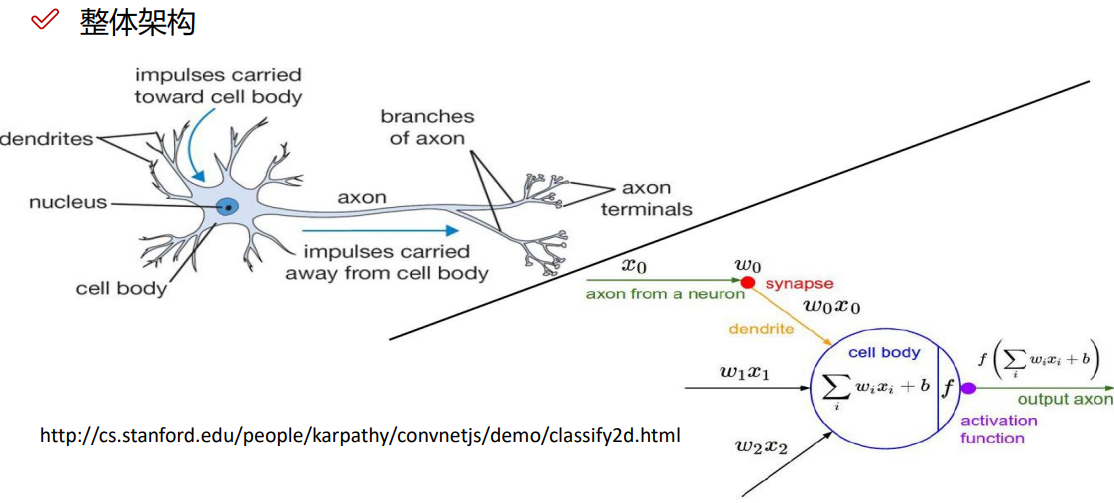
神经网络整体架构,有两种形式:
生物学上的
数学公式上的
我们只需要记住数学公式上的,权重参数求导,一系列的就行
数学上的:
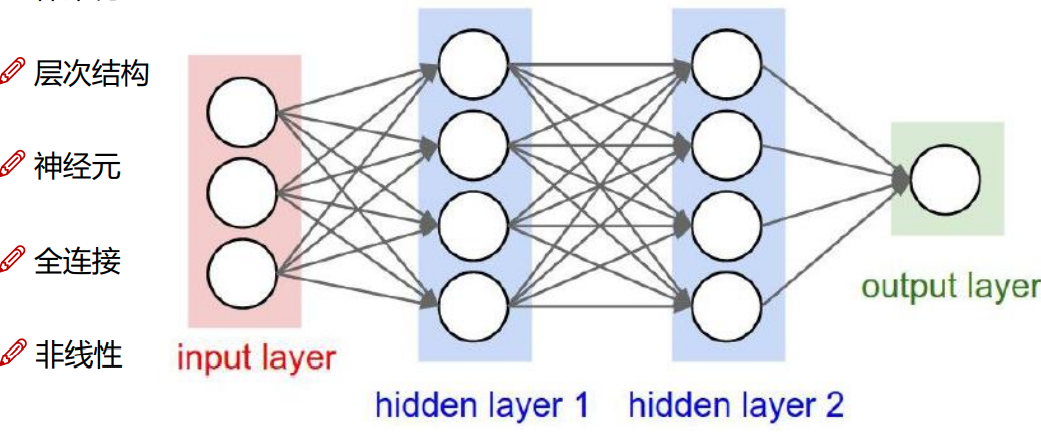
层次结构:神经网络是一层一层的进行优化和参数的传递
神经元:
input layer: 输入层,有几个特征就输入几个,每一个圆圈,就代表一个特征
hidden layer 1 : 输出层,将原始的输入特征,经过某种特殊的变换转换成,现有的几个特征,图中的权重矩阵是:3*4的
hidden layer 2 : 输入层,将前一层处理完之后的数据进行,在加工,在处理,在分类,能够更好的被计算机利用起来,图中的权重矩阵是4*4的
output layer : 通过某种操作转换成输出矩阵,该权重矩阵是4*1的
全连接:每层之间都需要全部链接起来
非线性:在通过权重矩阵处理完之后,我们还需要进行一些线性变换。然后在进行下一步的操作
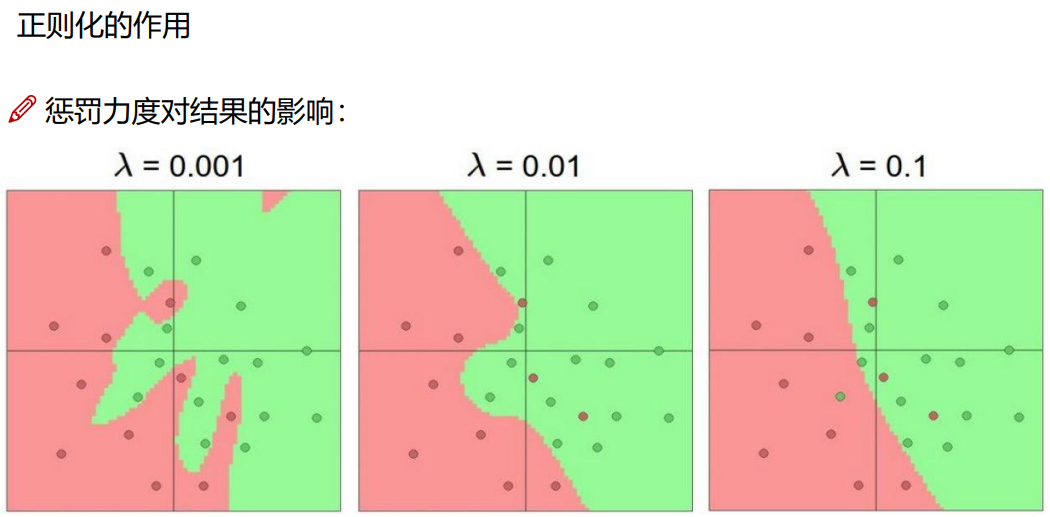
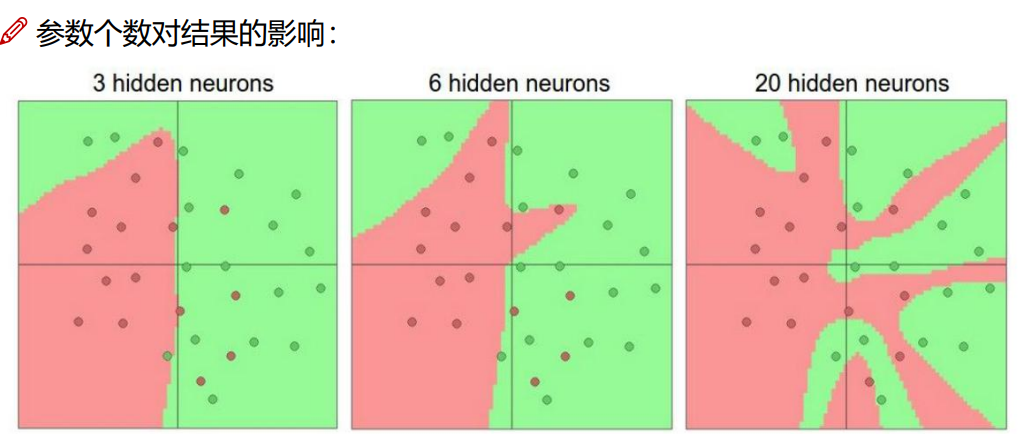
惩罚力度越大,过拟合风险越小
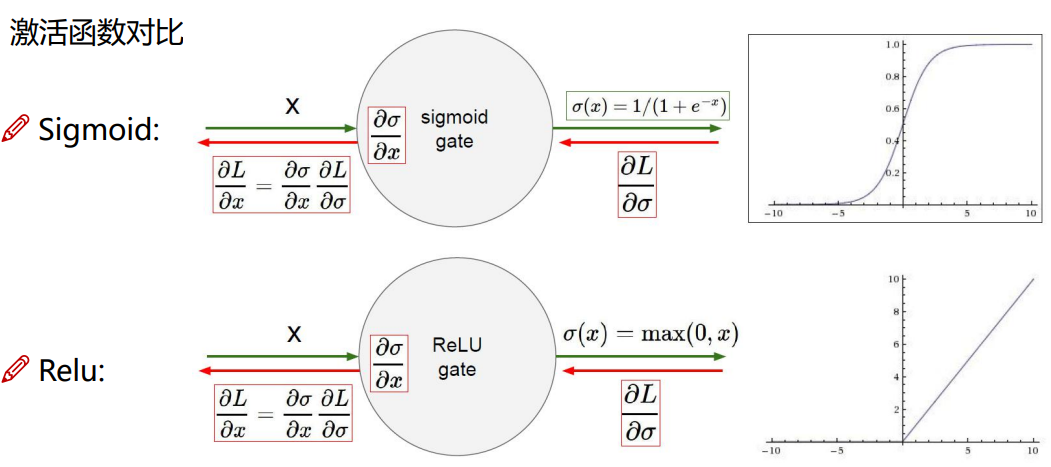
激活函数
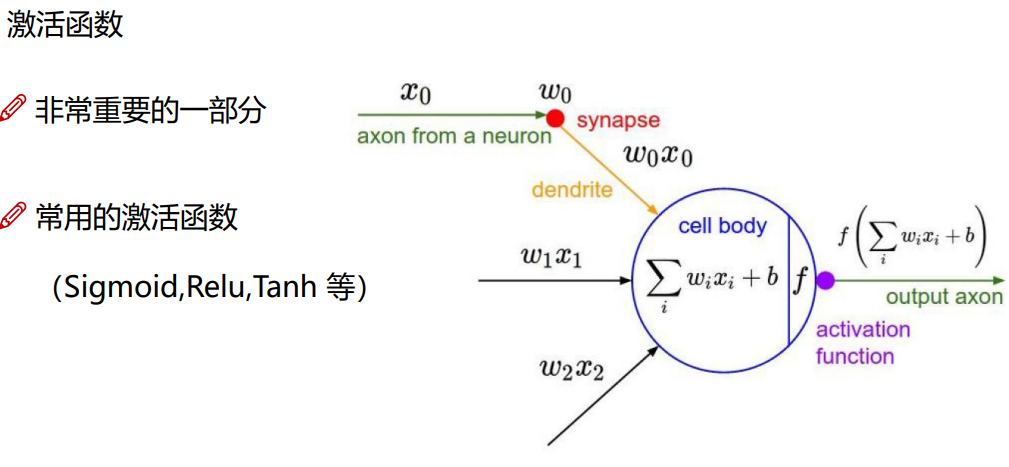
相比于sigmoid函数relu函数更加适用于神经网络
sigmoid:函数在进行求梯度的时候可能会出现梯度为零的情况
relu:不会出现梯度为零的情况
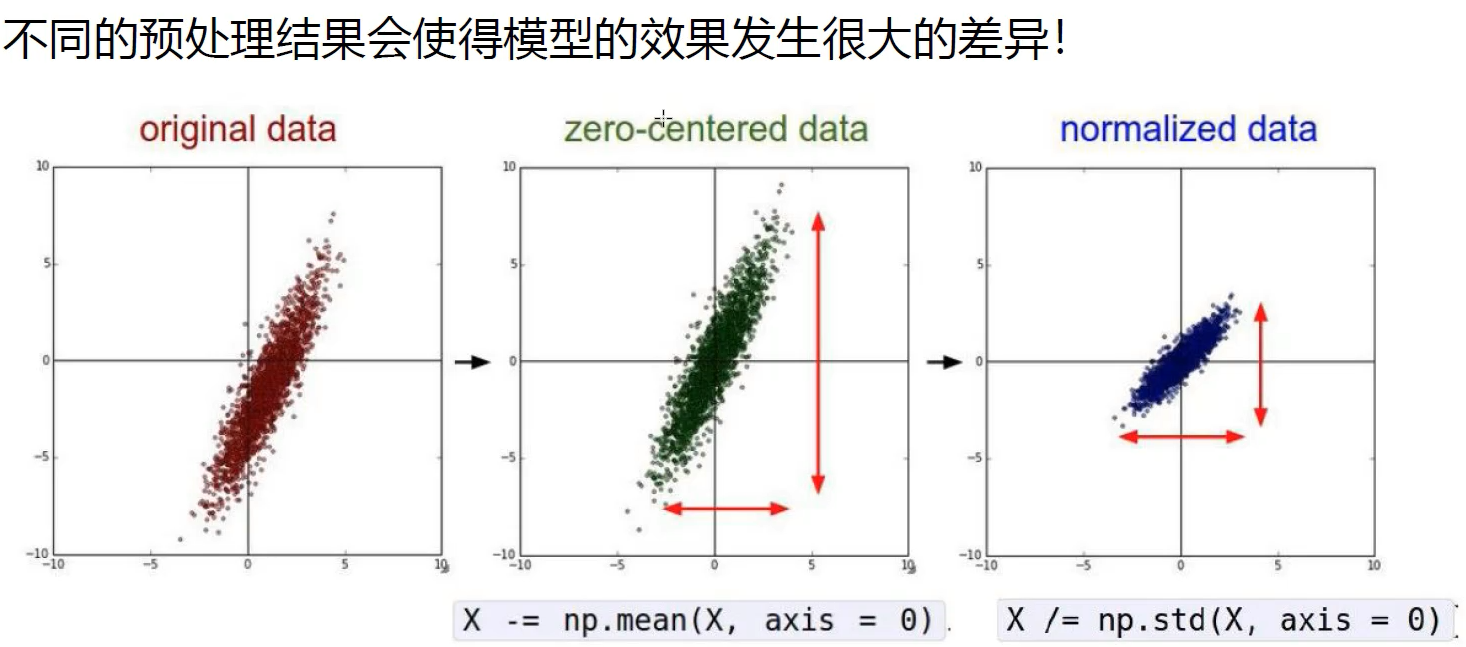
数据预处理
参数初始化
参数初始化同样十分重要
通常我们使用随机策略来进行参数的初始化
W = 0.01 * np.random.randn(D, H)
DROP-OUT
我们在训练数据的时候很可能出现过拟合风险,这时候我们可以在每一层训练的时候减少一些神经元,来减少过拟合的风险