SpringBoot响应式编程 Nuyoah 2024-09-26 2025-01-17 Function函数在java这个包中定义
java.util.function
Consumer是一个函数式接口**@FunctionalInterface在接口上添加这个注解可以帮助扫描该接口是否是函数式接口===>只能有一个为实现的方法**
Consumer里面accept方法是唯一的为实现的方法
接收参数但是不返回参数
1 2 3 Consumer<String> consumer = System.out::println; consumer.accept("Hello" );
Supplier里面的Get方法就是提供者方法
1 2 3 4 5 6 7 8 9 10 @FunctionalInterface public interface Supplier <T> { T get () ; }
不接收参数但是返回参数
1 2 3 4 Supplier<String> supplier = () -> "Hello" ; supplier.get();
Function中的apply多功能函数,能接口参数也能返回参数
1 2 3 4 @FunctionalInterface public interface Function <T, R> { R apply (T t) ; }
1 2 Function<String, String> function = String::toUpperCase; function.apply("Hello" );
1 2 3 4 @FunctionalInterface public interface Runnable { public abstract void run () ; }
例如开一个执行方法就是一个无入参无出参的函数
1 2 Runnable runnable = () -> System.out.println("Hello" );runnable.run();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 @FunctionalInterface public interface Predicate <T> { boolean test (T t) ; default Predicate<T> and (Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) && other.test(t); } default Predicate<T> negate () { return (t) -> !test(t); } default Predicate<T> or (Predicate<? super T> other) { Objects.requireNonNull(other); return (t) -> test(t) || other.test(t); } static <T> Predicate<T> isEqual (Object targetRef) { return (null == targetRef) ? Objects::isNull : object -> targetRef.equals(object); } @SuppressWarnings("unchecked") static <T> Predicate<T> not (Predicate<? super T> target) { Objects.requireNonNull(target); return (Predicate<T>)target.negate(); } }
通过传入参数进行逻辑判断,最后返回true OR false
1 2 3 4 5 Predicate<Integer> predicate = (a) -> a>10 ; predicate.test(10 ); predicate.negate().test(10 );
需要三部分
将操作对象转换成流
对流进行中间操作
filter
map
sorted
对流进行终结操作,只有在终结操作结束开始后,才会进行中间操作,否则中间操作不会执行
1 2 3 4 5 List<Integer> integers = List.of(1 , 2 , 3 , 4 , 5 ); integers.stream() .filter(integer -> integer % 2 == 0 ) .max(Integer::compareTo) .ifPresent(System.out::println);
Stream默认是不并发的,和for循环一样
可以使用**.parallel()**操作来让Stream流转换成并发操作
当时用并发之后,需要注意多线程安全问题
**有状态流:不推荐:**在流里面做出对流外面的数据进行操作
1 2 3 4 5 ArrayList<Integer> list = new ArrayList <>(); Arrays.asList(1 ,2 ,3 ,4 ,5 ).stream().filter(i -> { list.add(i); return i % 2 == 0 ; }).forEach(list::add);
**无状态流:推荐:**在流内部不对外部进行操作,数据状态只在此函数内有效,不溢出至流外
1 Stream<Integer> integerStream = Stream.of(1 , 2 , 3 );
创建流
1 Stream<Object> build = Stream.builder().add("11" ).add("22" ).add("33" ).build();
将两个Stream流合并到一起
1 Stream<Object> concat = Stream.concat(integerStream, build);
返回一个空的Stream流
1 2 Stream<Object> empty = Stream.empty(); empty.forEach(System.out::println);
如果传入参数是null,则返回一个空的Stream流,不是null则创建一个流
1 2 3 4 Stream<String> aaa = Stream.ofNullable("aaa" ); Stream<String> bbb = Stream.ofNullable(null ); aaa.forEach(System.out::println); bbb.forEach(System.out::println);
通过提供者函数提供的数据生成一个流
1 2 Stream<List<Integer>> generate = Stream.generate(() -> Arrays.asList(1 , 2 , 3 )); generate.forEach(System.out::println);
1 Arrays.asList(1 , 2 , 3 ).stream();
流里面的每一个元素都需要走完一个完整的流水线之后,才能轮到下一个元素走流程
过滤操作
filter函数内部传入的是一个Predicate ,断言操作,需要返回true或false,true则这元素通过审核,可以走下一步,否则直接断在这一步,轮到下一个元素上场
1 Arrays.asList(1 , 2 , 3 ).stream().filter(a -> a > 2 ).count
同类: mapToInt, mapToLong, mapToDouble
转换操作,一对一,一个元素转换成另一个元素
1 Arrays.asList(1 , 2 , 3 ).stream().map(t -> t + 1 ).forEach(System.out::println)
同类: flatMapToInt, flatMapToLong, flatMapToDouble
转换操作,一对多,一个元素转换成另多个元素,通过flatMap操作需要返回一个流
1 2 3 4 5 Arrays.asList(1 , 2 , 3 ) .stream() .map(t -> t + 1 ) .flatMap(t -> Arrays.asList(t, t+1 ).stream()) .forEach(System.out::println)
去重操作
排序操作,可传参数比较器 ,不传则默认
1 2 3 4 Arrays.asList(1 , 2 , 3 ) .stream() .sorted(Integer::compareTo) .forEach(System.out::println)
只对元素进行操作,不需要返回元素
限流,对流进行限制约束
1 2 3 4 5 Arrays.asList(1 , 2 , 3 ) .stream() .sorted(Integer::compareTo) .limit(1 ) .forEach(System.out::println)
进行过滤 ,和filter不同的是,filter过滤结果不符合要求之后会检查下一个,takeWhile不符合操作之后直接中断
遍历操作
计数操作
将结果返回成数组
1 2 3 4 5 Integer[] array = Arrays.asList(1 , 2 , 3 , 4 , 5 ).stream() .filter(i -> { list.add(i); return i % 2 == 0 ; }).distinct().sorted(Integer::compareTo).toArray(Integer[]::new );
将结果转换成List对象
1 2 3 4 5 List<Integer> collect = Stream.of(1 , 2 , 3 , 4 , 5 ) .filter(i -> { list.add(i); return i % 2 == 0 ; }).distinct().sorted(Integer::compareTo).collect(Collectors.toList());
将结果转换成Set对象,set和list的区别:SET中的元素不允许重复并且是无需的,LIST中的元素允许重复并且是有序的
将结果集转化成Map对象
toMap() 需要两个参数
参数1:生成键的Function函数
参数2:生成值的Function函数
注意:在使用toMap的时候键不能重复,否则会报键重复异常
1 2 3 4 5 Map<String, Integer> collect = Stream.of(1 , 2 , 3 , 4 , 5 ) .filter(i -> { list.add(i); return i % 2 == 0 ; }).distinct().collect(Collectors.toMap(i -> "key_" + i, i -> i));
返回结果
ReactiveStreams是JVM面向流的库的标准和规范
处理可能无限数量的元素
有序
在组件之间异步传递元素
强制性非阻塞背压模式
正压:正向压力,数据生产者给消费者的压力,数据生产多少个数据,消费者就需要去消费多少个数据,一次性生产过多数据,会导致消费时候压力巨大 ,例如前台给后端发送一万个请求,后台突然接到如此多的请求,一下子服务器压力倍增,导致服务器宕机
背压:背向压力:不正面对压力,使用流式处理,通过一个缓冲区,将多个数据放到缓冲区中,一条条处理,不管有再多的数据,服务端都是一条条处理,不会造成突然请求过多导致服务器崩溃
线程的数量是越多越好还是越少越好?
答:让线程的数量等于CPU的数量的时候最好
思想:让线程一直处于忙碌状态,不是让大量线程一直切换浪费时间
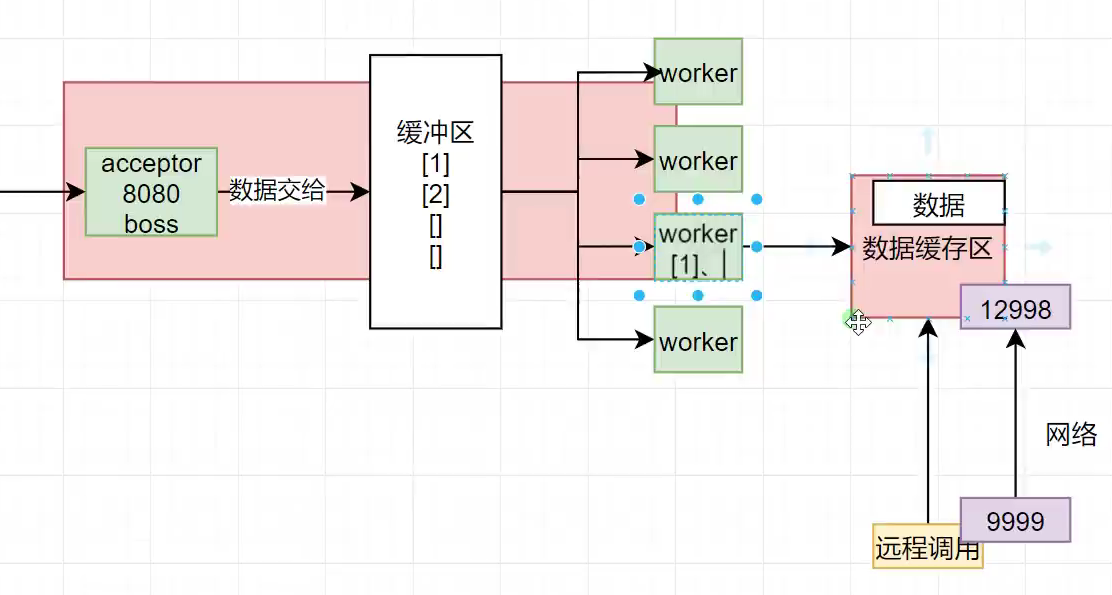
当浏览器发送大量请求的时候,Tomcat原本做法:会开好多个线程将请求接下,然后把线程分配给CPU,让CPU去处理这些请求 ,这样会导致线程频繁切换,浪费大量时间,流式思想:开一个BOSS线程去将这些请求全部接下,然后放到缓冲区,然后在开和CPU核心数量相同的WORKER线程,让线程去缓冲区中领任务 ,当WORKER遇到需要等待的数据时,worker会维护一个自己的 缓冲区,将需要数据等待的工程放到自己的缓冲区中等待数据的到来,然后自己再去主缓冲区中领任务
目的:通过全异步的方式、加缓存区构建一个 实时的数据流系统 。Kafka、MQ能构建出大型分布式的响应式系统。
缺本地化的消息系统解决方案:
让所有的异步线程能互相监听消息 ,处理消息 ,构建实时消息处理流
**响应式/声明式编程:**说清楚要干什么,最终结果是怎么样即可
数据是自动流的,而不是靠迭代被动流动的
推拉模型:
推:流模式,上流有数据,自动流到下流
拉:迭代式:自己遍历,自己拉取数据
Publisher:发布者;产生数据流
Subscriber:订阅者;消费数据流
Subscription:订阅关系;
订阅关系是发布者和订阅者之间的关键接口。订阅者通过订阅来表示对发布者产生的数据的兴趣。订阅者可以请求一定数量的元素,也可以取消订阅。
Processor:处理器
处理器是同时实现了发布者和订阅者接口的组件 。它可以接收来自一个发布者的数据,进行处理,并将结果发布给下一个订阅者。处理器在Reactor中充当中间环节,代表一个处理阶段,允许你在数据流中进行转换、过滤和其他操作。
用来发布数据,将数据发布到缓冲区中
创建publisher
1 2 3 4 5 6 7 8 9 Flow.Publisher<String> publisher = new Flow .Publisher<String>() { private Flow.Subscriber<? super String> subscriber; @Override public void subscribe (Flow.Subscriber<? super String> subscriber) { this .subscriber = subscriber; } };
创建一个提交发布者,向缓冲区中提交数据,然后订阅者可以从缓冲区中取出数据
1 2 3 4 5 try (SubmissionPublisher<String> stringSubmissionPublisher = new SubmissionPublisher <>()) { for (int i = 0 ; i < 10 ; i++) { stringSubmissionPublisher.submit("Hello " + i); } }
submissionPublisher通过submit方法将指定数据存入Publisher中的buffer容器中
submit通过调用doOffer方法,将item传入
doOffer中有个BufferedSubscription订阅者调用offer方法将item放入缓冲区中
通过调用growAndOffer将数据放入Publisher的缓冲区中
订阅者,订阅发布者,可以获取到发布者的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 SubmissionPublisher<String> publisher = new SubmissionPublisher <>(); Flow.Subscriber<String> subscriber = new Flow .Subscriber<>() { private Flow.Subscription subscription; @Override public void onSubscribe (Flow.Subscription subscription) { this .subscription = subscription; System.out.println(Thread.currentThread().getName() + "订阅开始了,关系:" + subscription); subscription.request(1 ); } @Override public void onNext (String item) { System.out.println(Thread.currentThread() + "订阅者,接收到新数据" + item); if (item.equals("7" )) subscription.cancel(); subscription.request(1 ); } @Override public void onError (Throwable throwable) { System.out.println(Thread.currentThread() + "订阅者,发生错误,错误信息:" + throwable); } @Override public void onComplete () { System.out.println(Thread.currentThread() + "订阅者,订阅结束" ); } }; publisher.subscribe(subscriber); for (int i = 0 ; i < 10 ; i++) { publisher.submit(String.valueOf(i)); } publisher.close(); Thread.sleep(20000 );
处理器,定义中间操作
每一个中间处理器Processor都是一个发布者和订阅者
Publisher通过subscribe绑定订阅者,Publisher会有一个订阅者列表,里面记录着所有的订阅者,当有数据的时候,所有的订阅者都可以获取到数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 static class MyProcessor extends SubmissionPublisher <String> implements Flow .Processor<String, String> { private Flow.Subscription subscription; @Override public void onSubscribe (Flow.Subscription subscription) { this .subscription = subscription; System.out.println("中间处理器开始处理数据" + subscription); subscription.request(1 ); } @Override public void onNext (String item) { System.out.println("处理这开始处理数据:" + item); item = item + ": 哈哈" ; submit(item); subscription.request(1 ); } @Override public void onError (Throwable throwable) { System.out.println(Thread.currentThread() + "处理器,发生错误,错误信息:" + throwable); } @Override public void onComplete () { System.out.println(Thread.currentThread() + "处理器,订阅结束" ); } }
设置关系
设置发布者,中间处理器,和订阅者之间的关系
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 SubmissionPublisher<String> publisher = new SubmissionPublisher <>(); Flow.Subscriber<String> subscriber = new Flow .Subscriber<>() { private Flow.Subscription subscription; @Override public void onSubscribe (Flow.Subscription subscription) { this .subscription = subscription; System.out.println(Thread.currentThread().getName() + "订阅开始了,关系:" + subscription); subscription.request(1 ); } @Override public void onNext (String item) { System.out.println(Thread.currentThread() + "订阅者,接收到新数据" + item); if (item.equals("7" )) subscription.cancel(); subscription.request(1 ); } @Override public void onError (Throwable throwable) { System.out.println(Thread.currentThread() + "订阅者,发生错误,错误信息:" + throwable); } @Override public void onComplete () { System.out.println(Thread.currentThread() + "订阅者,订阅结束" ); } }; MyProcessor processor1 = new MyProcessor ();MyProcessor processor2 = new MyProcessor ();MyProcessor processor3 = new MyProcessor ();publisher.subscribe(processor1); processor1.subscribe(processor2); processor2.subscribe(processor3); processor3.subscribe(subscriber); for (int i = 0 ; i < 10 ; i++) { publisher.submit(String.valueOf(i)); } publisher.close(); Thread.sleep(2000 );
响应式编程:
底层 :基于数据缓冲队列 +消息驱动模型 +异步回调机制 编码 :流式编程 +链式调用 +声明式API 效果 :优雅全异步 +消息实时处理 +高吞吐量 +占用少量资源
解决痛点:
以前要做高并发系统:缓存,异步,队排好,需要我们手动控制整个逻辑
现在:全自动控制整个逻辑 ,我们只需要组装好数据处理流水线即可
少量线程一直运行 > 大量线程切换等待
Reactor官网
三大核心
Reactor Core:Reactor核心,非阻塞线程
两种数据类型:FLUX多数据,MONO(0或1)
非阻塞IO
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 <?xml version="1.0" encoding="UTF-8" ?> <project xmlns ="http://maven.apache.org/POM/4.0.0" xmlns:xsi ="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation ="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd" > <modelVersion > 4.0.0</modelVersion > <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 3.4.0</version > <relativePath /> </parent > <groupId > com.nuyoah</groupId > <artifactId > ReactiveProgramming</artifactId > <version > 1.0-SNAPSHOT</version > <packaging > pom</packaging > <modules > <module > stream</module > <module > reactor</module > </modules > <properties > <maven.compiler.source > 17</maven.compiler.source > <maven.compiler.target > 17</maven.compiler.target > <project.build.sourceEncoding > UTF-8</project.build.sourceEncoding > <reactor-bom.version > 2024.0.0</reactor-bom.version > <reactor-test.version > 3.7.0</reactor-test.version > <reactor-core.version > 3.7.0</reactor-core.version > </properties > <dependencyManagement > <dependencies > <dependency > <groupId > io.projectreactor</groupId > <artifactId > reactor-bom</artifactId > <version > ${reactor-bom.version}</version > <type > pom</type > </dependency > <dependency > <groupId > io.projectreactor</groupId > <artifactId > reactor-core</artifactId > <version > ${reactor-core.version}</version > </dependency > <dependency > <groupId > io.projectreactor</groupId > <artifactId > reactor-test</artifactId > <version > ${reactor-test.version}</version > <scope > test</scope > </dependency > </dependencies > </dependencyManagement > </project >
数据流:每一个元素从流的源头,开始源源不断,自己往下滚动
onNext:当元素到达时需要处理的操作
onComplete:当元素都处理完之后进行的操作
onError:当元素处理出现错误的时候进行的操作
一个数据流:元素(0-N) + 结束信号(1:正常/出错)
流经过运算之后(operator)会得到一个新流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main (String[] args) throws IOException { Flux<Integer> just = Flux.just(1 , 2 , 3 , 4 , 5 ); just.subscribe(e -> System.out.println("e1: " + e)); just.subscribe(e -> System.out.println("e2: " + e)); Flux<Long> interval = Flux.interval(Duration.ofSeconds(1 )); interval.subscribe(e -> System.out.println("interval: " + e)); System.in.read(); }
1 2 3 4 5 6 public static void main (String[] args) { Mono<Integer> just = Mono.just(1 ); just.subscribe(System.out::println); }
在链式API中下面操作会消耗上面流
doOnComplete()
在流中的元素消费结束之后的回调方法
1 2 3 4 Flux<Integer> just = Flux.just(1 , 2 , 3 , 4 , 5 ).doOnComplete(() -> System.out.println("Done" )); just.subscribe(e -> System.out.println("e1: " + e));
在just中的内容消费结束之后会调用输出Done的方法
delayElements()
整流操作,将流中的的元素以相同的时间间隔发布出去
当流中的元素的以不规律的方式传入流中的时候,通过整流操作以规整的方式将数据传出去
1 2 3 4 5 6 Flux<Integer> just = Flux.just(1 , 2 , 3 , 4 , 5 ) .doOnComplete(() -> System.out.println("Done" )) .delayElements(Duration.ofSeconds(1 )); just.subscribe(e -> System.out.println("e1: " + e));
订阅的时候元素流动速度是1s一个
doOnCancle
当流被取消的时候,调用此方法
1 2 3 4 5 Flux<Integer> just = Flux.just(1 , 2 , 3 , 4 , 5 ) .delayElements(Duration.ofSeconds(1 )); Flux<Integer> integerFlux = just.doOnCancel(() -> System.out.println("Cancelled" ));
doOnError()
当流出现错误的时候调用此方法
1 2 3 4 5 Flux<Integer> just = Flux.just(1 , 2 , 3 , 4 , 5 ) .delayElements(Duration.ofSeconds(1 )); Flux<Integer> integerFlux = just.doOnError(e -> System.out.println("Error" ));
doOnNext
当流下一个元素到达时调用此方法
1 2 3 4 5 6 Flux<Integer> just = Flux.just(1 , 2 , 3 , 4 , 5 ) .delayElements(Duration.ofSeconds(1 )); Flux<Integer> integerFlux = just .doOnNext(System.out::println);
doOnEach
处理所有的流中的元素包括信号 ,doOnNext是处理流中的元素不包括信号
doOnRequest
当使用request方法获取流的时候,会调用此方法,参数为request请求的数量
使用 integerFlux.subscribe(e -> System.out.println("e1: " + e)); 这种方法的时候,会一次性调用所有的流,request(Long.MAX_VALUE)
1 2 3 4 5 6 7 8 9 Flux<Integer> just = Flux.just(1 , 2 , 3 , 4 , 5 ) .delayElements(Duration.ofSeconds(1 )); Flux<Integer> integerFlux = just.doOnComplete(() -> System.out.println("Done" )) .doOnError(e -> System.out.println("Error" )) .doOnRequest(e -> System.out.println("Request: " + e)) .doOnCancel(() -> System.out.println("Cancelled" )); integerFlux.subscribe(e -> System.out.println("e1: " + e));
所有的doOn方法都是消耗上面的流
1 2 3 4 5 6 Flux<Integer> integerFlux = just .map(intNum -> 10 /intNum) .doOnError(e -> System.out.println("10除出错" )) .map(intNum -> 100 /intNum) .doOnError(e -> System.out.println("100除出错" )) ;
SUBSCRIBE:被订阅
REQUEST:被请求元素
CANCLE:取消订阅的时候
ON_SUBSCRIBE:在订阅的时候
ON_NEXT:在元素到达的时候
ON_ERROR:在发生错误的时候
ON_COMPLETE:在流正常完成的时候
AFTER_TERMINATE:中断以后
CURRENT_CONTEXT:当前的上下文
ON_CONTEXT:感知上下文
使用 .log方法,同样的,log也是只会记录上一个流处理的操作
1 2 3 4 5 6 Flux<Integer> integerFlux = just .map(intNum -> 10 /intNum) .log() .map(intNum -> 100 /intNum) .log() ;
流只有在被订阅之后,流中的元素才会被处理,只要不被订阅,则流中的元素所设置的操作都不会被执行
subscribe的几种参数
空订阅者 ,订阅之后对流中的元素没有进行任何操作
1 2 3 4 5 6 7 // 生成一个流,当流没有被订阅的时候,map中的操作不会被执行 Flux<String> flux = Flux.range(1, 10) .map(i -> { return "哈哈: " + i; }); // 流被订阅,则map中的操作会背执行 flux.subscribe();
传入一个消费者
1 2 3 4 5 6 7 8 9 10 11 Flux<String> flux = Flux.range(1 , 10 ) .map(i -> { String s = "哈哈: " + i; System.out.printf("元素:%s 到达%n" , i); return s; }); flux.subscribe(n -> { System.out.println("处理元素值:" + n); });
返回值结果,由此可见,当流被订阅的时候,流中的元素会依次进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 元素:1 到达 处理元素值:哈哈: 1 元素:2 到达 处理元素值:哈哈: 2 元素:3 到达 处理元素值:哈哈: 3 元素:4 到达 处理元素值:哈哈: 4 元素:5 到达 处理元素值:哈哈: 5 元素:6 到达 处理元素值:哈哈: 6 元素:7 到达 处理元素值:哈哈: 7 元素:8 到达 处理元素值:哈哈: 8 元素:9 到达 处理元素值:哈哈: 9 元素:10 到达 处理元素值:哈哈: 10
传入一个消费者和一个错误消费者
当流中出现错误的时候可以由errorconsumer来进行处理,也可由doOnerror来进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Flux<String> flux = Flux.range(1 , 10 ) .map(i -> { if (i == 3 ){ i = 10 / (i-3 ); } String s = "哈哈: " + i; System.out.printf("元素:%s 到达%n" , i); return s; }); flux.subscribe( n -> System.out.println("处理元素值:" + n), throwable -> System.out.println("出现错误:" +throwable.getMessage()) );
返回结果,当出现错误的时候,错误结果被errorConsumer进行处理,流中值运行
1 2 3 4 5 元素:1 到达 处理元素值:哈哈: 1 元素:2 到达 处理元素值:哈哈: 2 出现错误:/ by zero
传入三个消费者,第一个正常消费,第二个捕获错误信息,第三个捕获完成信息
1 2 3 4 5 6 7 8 9 10 11 12 13 Flux<String> flux = Flux.range(1 , 3 ) .map(i -> { String s = "哈哈: " + i; System.out.printf("元素:%s 到达%n" , i); return s; }); flux.subscribe( n -> System.out.println("处理元素值:" + n), throwable -> System.out.println("出现错误:" +throwable.getMessage()), () -> System.out.println("流正常结束" ) );
结果显示
1 2 3 4 5 6 7 元素:1 到达 处理元素值:哈哈: 1 元素:2 到达 处理元素值:哈哈: 2 元素:3 到达 处理元素值:哈哈: 3 流正常结束
实现BaseSubscriber 进行消费者的自定义实现
消费者中有各种回调方法
可以实现如下方法
BaseSubscriber中实现的很多方法方便我们调用,例如request等等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 Flux<String> flux = Flux.range(1 , 3 ) .map(i -> { String s = "哈哈: " + i; System.out.printf("元素:%s 到达%n" , i); return s; }); flux.subscribe( new BaseSubscriber <String>() { @Override protected void hookOnSubscribe (Subscription subscription) { System.out.println("开始订阅" ); request(1 ); } @Override protected void hookOnNext (String value) { System.out.println("元素到达" + value); request(1 ); } @Override protected void hookOnComplete () { super .hookOnComplete(); } @Override protected void hookOnError (Throwable throwable) { super .hookOnError(throwable); } @Override protected void hookOnCancel () { super .hookOnCancel(); } } );
流可以被消费者使用cancel方法随时取消流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Flux<String> flux = Flux.range(1 , 3 ) .map(i -> { String s = "哈哈: " + i; System.out.printf("元素:%s 到达%n" , i); return s; }); flux.subscribe( new BaseSubscriber <String>() { @Override protected void hookOnSubscribe (Subscription subscription) { System.out.println("开始订阅" ); request(1 ); } @Override protected void hookOnNext (String value) { if (value.contains("2" )) cancel(); System.out.println("元素到达" + value); request(1 ); } @Override protected void hookOnCancel () { System.out.println("流被取消了" ); } } );
是消费者像生产者请求数据的时候,生产者才会给消费者数据,请求一个给一个,请求几个给几个。
好处:虽然生产者多很多数据,但是只有在消费者请求的时候才能给消费者数据,不会因为生产数据过多导致消费者压力过大崩溃
通过设置缓冲区,将流中的元素进行缓冲区分开,默认缓冲区为1
request(N):找发布者请求N次数据,总共能得到N*bufferSize个数据
当不使用buffer的时候,我们通过request(1) 是请求了一个数据,当时用buffer之后,我们通过request(1) 是请求了1*buffersize个数据
request3和buffer(3) 不一样,request3表明一次请求三个数据,那么生产者会一次发一条数据,发三次,使用buffer(3)生产者会一次发三个数据发一次。用doOnNext的话就是第一个触发了三次doOnNext,第二个触发了一次doOnNext
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 Flux<List<String>> buffer = Flux.range(1 , 3 ) .map(i -> { return "哈哈: " + i; }) .buffer(2 ); buffer.subscribe( new BaseSubscriber <List<String>>() { @Override protected void hookOnSubscribe (Subscription subscription) { System.out.println("开始订阅" ); request(1 ); } @Override protected void hookOnNext (List<String> value) { System.out.println(value); request(1 ); } } );
结果
1 2 3 开始订阅 [哈哈: 1 , 哈哈: 2 ] [哈哈: 3 ]
限制请求速率,并且有预抓取策略 ,当设置的请求大小中已经与75%的数据被消费了之后 ,会自动请求下一个请求速率*75%的元素
发布者发布100个数据,并设置请求速率为10,那么在第一次请求的时候会请求10个,当10个中75%的数据被消费之后,会自动请求下面75%的
1 2 3 4 Flux.range(1 , 100 ) .log() .limitRate(10 ) .subscribe(System.out::println);
结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 23 :10 :20.512 [main] INFO reactor.Flux.Range.1 -- | onSubscribe([Synchronous Fuseable] FluxRange.RangeSubscription)23 :10 :20.522 [main] INFO reactor.Flux.Range.1 -- | request(10 )23 :10 :20.523 [main] INFO reactor.Flux.Range.1 -- | onNext(1 )1 23 :10 :20.523 [main] INFO reactor.Flux.Range.1 -- | onNext(2 )2 23 :10 :20.524 [main] INFO reactor.Flux.Range.1 -- | onNext(3 )3 23 :10 :20.524 [main] INFO reactor.Flux.Range.1 -- | onNext(4 )4 23 :10 :20.524 [main] INFO reactor.Flux.Range.1 -- | onNext(5 )5 23 :10 :20.524 [main] INFO reactor.Flux.Range.1 -- | onNext(6 )6 23 :10 :20.524 [main] INFO reactor.Flux.Range.1 -- | onNext(7 )7 23 :10 :20.524 [main] INFO reactor.Flux.Range.1 -- | onNext(8 )8 23 :10 :20.525 [main] INFO reactor.Flux.Range.1 -- | request(8 ) 23 :10 :20.525 [main] INFO reactor.Flux.Range.1 -- | onNext(9 )9
buffer是放到缓冲区中request一次请求buffer个数据,limitReat是一次性取设置的速率次数的值,如果buffer是10,limitReat是100,如果不适用限流的话会一次性全部取出,进行限流之后第一次会请求100次一次是buffer大小的数据,从第二次开始实行预抓取策略,请求的次数是设置的75%
想通过自定义一系列函数来创建序列,可以有以下几种方式
通过设置初始值来开始元素的生成
通过sink的next方法来处理我们需要发布什么数据出去
通过return来决定下一次处理数据的最新状态
1 2 3 4 5 6 7 8 9 10 11 12 Flux<Object> generate = Flux.generate( () -> 0 , (state, sink) -> { if (state < 10 ) { sink.next(state); } else { sink.complete(); } return state + 1 ; }); generate.log() .subscribe();
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Flux.create(fluxSink -> { MyListener myListener = new MyListener (fluxSink); for (int i = 0 ; i < 10 ; i++) { myListener.online("hh-" +i); } }).subscribe(); } public static class MyListener { private final FluxSink<Object> fluxSink; public MyListener (FluxSink<Object> fluxSink) { this .fluxSink = fluxSink; } public void online (String username) { System.out.println(username+"上线了" ); fluxSink.next(username); } }
在上面的一系列方法中例如 .map, .filter中进行流的中间操作,现在可以使用自定义处理方法来处理操作
**handle和map的区别:**map需要返回值类型必须是统一的,handle没有这个限制
1 2 3 4 5 6 7 8 9 10 11 Flux.range(1 , 10 ) .handle((value, sink) -> { System.out.println("value: " + value); value = value * 2 ; sink.next(value); }) .log() .subscribe();
Schedulers.immediate() : 默认线程池
Schedulers.single() : 创建一个单个线程池
Schedulers.boundedElastic() : 创建一个多个线程池,线程个数 10*cpu核心数,存活时间60s
使用publishOn切换发布者线程,使用subscribeOn切换接受者线程池
如果不切换线程池的话,上面一些操作默认都是在主线程下执行的
1 2 3 4 Flux.range(1 , 1000 ) .publishOn(Schedulers.boundedElastic()) .log() .subscribe();
只要发布者不指定线程,则默认使用订阅者的线程 ,因为流只有在被订阅的时候才会流动。
过滤操作,需要返回true或false,false的过滤掉
1 2 3 4 Flux.just(1 ,2 ,3 ,4 ) .filter(i -> i % 2 == 0 ) .log() .subscribe();
结果只有为偶数的元素流下来了
首先是流被订阅
后来请求无限个元素
最后偶数元素到达
1 2 3 4 5 6 7 8 21 :24 :21.918 [main] INFO reactor.Flux.FilterFuseable.1 -- | onSubscribe([Fuseable] FluxFilterFuseable.FilterFuseableSubscriber)21 :24 :21.923 [main] INFO reactor.Flux.FilterFuseable.1 -- | request(unbounded)21 :24 :21.924 [main] INFO reactor.Flux.FilterFuseable.1 -- | onNext(2 )21 :24 :21.924 [main] INFO reactor.Flux.FilterFuseable.1 -- | onNext(4 )21 :24 :21.924 [main] INFO reactor.Flux.FilterFuseable.1 -- | onNext(6 )21 :24 :21.924 [main] INFO reactor.Flux.FilterFuseable.1 -- | onNext(8 )21 :24 :21.924 [main] INFO reactor.Flux.FilterFuseable.1 -- | onNext(10 )21 :24 :21.924 [main] INFO reactor.Flux.FilterFuseable.1 -- | onComplete()
将日志打印在上面
1 2 3 4 Flux.just(1 ,2 ,3 ,4 ) .log() .filter(i -> i % 3 == 0 ) .subscribe();
首先订阅元素
其次是订阅者请求无限个元素
第一个元素到达
filter发现第一个元素无法对3取余,所以请求了下一个元素,第二元素也无法对3取余,filter有请求了一次,直到第三个符合要求,就没有在请求了,背压模式
1 2 3 4 5 6 7 8 9 10 21 :31 :24.507 [main] INFO reactor.Flux.Array.1 -- | onSubscribe([Synchronous Fuseable] FluxArray.ArrayConditionalSubscription)21 :31 :24.512 [main] INFO reactor.Flux.Array.1 -- | request(unbounded)21 :31 :24.513 [main] INFO reactor.Flux.Array.1 -- | onNext(1 )21 :31 :24.513 [main] INFO reactor.Flux.Array.1 -- | request(1 )21 :31 :24.514 [main] INFO reactor.Flux.Array.1 -- | onNext(2 )21 :31 :24.514 [main] INFO reactor.Flux.Array.1 -- | request(1 )21 :31 :24.514 [main] INFO reactor.Flux.Array.1 -- | onNext(3 )21 :31 :24.514 [main] INFO reactor.Flux.Array.1 -- | onNext(4 )21 :31 :24.514 [main] INFO reactor.Flux.Array.1 -- | request(1 )21 :31 :24.514 [main] INFO reactor.Flux.Array.1 -- | onComplete()
将流一个元素转换成多个元素,无序的发往下流
1 2 3 4 5 6 7 Flux.just("zhang san" , "li si" ) .flatMap(i -> { String[] s = i.split(" " ); return Flux.fromArray(s); }) .log() .subscribe();
输入日志
1 2 3 4 5 6 7 21 :48 :29.772 [main] INFO reactor.Flux.FlatMap.1 -- onSubscribe(FluxFlatMap.FlatMapMain)21 :48 :29.777 [main] INFO reactor.Flux.FlatMap.1 -- request(unbounded)21 :48 :29.778 [main] INFO reactor.Flux.FlatMap.1 -- onNext(zhang)21 :48 :29.778 [main] INFO reactor.Flux.FlatMap.1 -- onNext(san)21 :48 :29.779 [main] INFO reactor.Flux.FlatMap.1 -- onNext(li)21 :48 :29.779 [main] INFO reactor.Flux.FlatMap.1 -- onNext(si)21 :48 :29.779 [main] INFO reactor.Flux.FlatMap.1 -- onComplete()
同样是将一个元素转换成多个元素,但是concatMap是有序的
1 2 3 4 Flux.just(1 ,2 ,3 ) .concatMap(i -> Flux.just(i, i*2 )) .log() .subscribe();
为什么FlatMap是无序的而concatMap是有序的?
因为FlatMap是并发处理元素的,当一个元素到达之后,Flat进行元素的处理,不等这个元素处理完flatmap就会请求下一个元素
当第一个元素处理慢,而第二个元素处理快的时候,第二个元素就会优先流往下流,导致顺序出错
将两个流转换合并成新流,不做任何操作
1 2 3 Flux.concat(Flux.range(1 , 3 ), Flux.range(3 , 5 )) .log() .subscribe();
将老流连接上新流
1 2 3 4 Flux.just(1 ,2 ,3 ) .concatWith(Flux.just(4 ,5 ,6 )) .log() .subscribe();
转换流中的数据
将流中的数据整体转换成另一种数据
transform接收的是一个上流传过来的Flux流,将流中的元素进行转换之后,送个下流
一个流的一个Transform只会执行一次
1 2 3 4 5 6 7 8 9 10 11 12 AtomicInteger atomic = new AtomicInteger (1 );Flux<String> transformFlux = Flux.just("a" , "b" , "c" ) .transform(value -> { System.out.println("Transform执行了-" + atomic.get()); if (atomic.getAndIncrement() == 1 ) { return value.map(String::toUpperCase); } else { return value; } }); transformFlux.subscribe(System.out::println); transformFlux.subscribe(System.out::println);
执行结果
1 2 3 4 5 6 7 Transform执行了-1 A B C A B C
同样是将流转换成一个新流,不过是有一个订阅者就会执行一次转换
1 2 3 4 5 6 7 8 9 10 11 12 AtomicInteger atomic = new AtomicInteger (1 );Flux<String> transformFlux = Flux.just("a" , "b" , "c" ) .transformDeferred(value -> { System.out.println("Transform执行了-" + atomic.get()); if (atomic.getAndIncrement() == 1 ) { return value.map(String::toUpperCase); } else { return value; } }); transformFlux.subscribe(System.out::println); transformFlux.subscribe(System.out::println);
执行结果
1 2 3 4 5 6 7 8 Transform执行了-1 A B C Transform执行了-2 a b c
发布出一个空元素
如果想要发布出一个空元素,需要使用Empty来进行发布
1 2 3 Mono<Object> empty = Mono.empty(); empty.defaultIfEmpty("aaa" ) .subscribe();
可以判断当流中的元素为空的时候,设置一个默认值
静态兜底方法
1 2 3 Mono<Object> empty = Mono.empty(); empty.defaultIfEmpty("aaa" ) .subscribe();
switchIfEmpty
动态兜底方法
判断流中元素是否为空,如果为空怎调用一个方法来返回值
1 2 3 4 5 6 7 8 9 10 @Test public void emptyTest () { Mono<Object> empty = Mono.empty(); empty.switchIfEmpty(haha()) .subscribe(System.out::println); } private Mono<?> haha() { return Mono.just("123" ); }
将多个流进行合并,并且按照元素发布的时间进行合并
1 2 Flux.merge(Flux.range(1 , 3 ), Flux.range(3 , 5 )) .subscribe(System.out::println);
将老流合并到新流中
1 2 3 Flux.range(1 , 3 ) .mergeWith(Flux.range(3 , 5 )) .subscribe(System.out::println);
按照那个流先发先合并那个
1 2 Flux.mergeSequential(Flux.range(1 , 3 ), Flux.range(3 , 5 )) .subscribe(System.out::println);
将多个流中的元素进行打包,打包成一个元组
1 2 3 4 5 6 7 8 Flux.zip(Flux.range(1 , 3 ), Flux.range(3 , 5 ), Flux.just("a" , "b" , "c" )) .map(tuple -> { Integer t1 = tuple.getT1(); Integer t2 = tuple.getT2(); String t3 = tuple.getT3(); return t1 + t2 + t3; }) .subscribe(System.out::println);
直接获取第一个数据,无需通过订阅者
1 2 3 Integer i = Flux.just(1 ,2 ,3 ,4 ) .next() .block();
错误是一种中断信息,不是流结束信息
订阅者可以感知流的正确与错误信息
在订阅的时候,可以传入三个消费者
流正常时的消费者,流错误时的消费者,流结束时的消费者
捕获并返回
Catch and return a static default value.
在命令式编程中,以下面这种方式捕获并返回信息
1 2 3 4 5 6 7 8 9 try { for (int i = 1 ; i < 11 ; i++) { String v1 = doSomethingDangerous(i); String v2 = doSecondTransform(v1); System.out.println("RECEIVED " + v2); } } catch (Throwable t) { System.err.println("CAUGHT " + t); }
在流式编程中使用onErrorReturn 方法实现上面的方式
onErrorReturn 无法直接跟在流初始化的后面,需要跟在中间操作后面
1 2 3 Flux.just(10 ) .map(this ::doSomethingDangerous) .onErrorReturn("RECOVERED" );
特性
会捕获处理异常,消费者无异常感知
返回一个默认值
中断流操作,流正常完成
捕获并调用回调方法
在命令式编程中此方法是
1 2 3 4 5 6 try { v1 = callExternalService("key1" ); } catch (Throwable error) { v1 = getFromCache("key1" ); }
Catch and execute an alternative path with a fallback method.
1 2 3 Flux.just(10 ,20 ,30 ) .map(this ::doSomethingDangerousOn30) .onErrorResume(err -> Mono.just(40 ));
特性
可以捕获异常,消费者无感知
当发生异常之后会调用一个自定义方法
流中断,正常返回
Catch and dynamically compute a fallback value.
1 2 3 4 Flux.just(10 ,20 ,30 ) .map(this ::doSomethingDangerousOn30) .onErrorResume(err -> handleErrorMethod(error));
使用onErrorResume+Flux.error 执行该操作
Catch, wrap to a BusinessException, and re-throw.
1 2 3 Flux.just(10 ,20 ,30 ) .map(this ::doSomethingDangerousOn30) .onErrorResume(err -> Flux.error(new MyException (error)));
消费者会感知到异常
使用onErrorMap来执行该操作
1 2 3 Flux.just(10 ,20 ,30 ) .map(this ::doSomethingDangerousOn30) .onErrorMap(err -> new MyException (error));
特点
捕获异常
抛出新异常
消费者有感知
流异常结束
Catch, log an error-specific message, and re-throw.
捕获异常并且对异常进行记录 ,消费者有感知
在命令式编程中实现方法如此
1 2 3 4 5 6 7 8 try { return callExternalService(k); } catch (RuntimeException error) { log("uh oh, falling back, service failed for key " + k); throw error; }
在响应式编程中实现方法如下
1 2 3 4 5 Flux.just("1" ,"2" ,"3" ) .map(this ::myMethod) .doOnError(error -> { log.error("感知到异常" ) })
特点
捕获异常,并做一些自己的事情
将异常继续向下抛出
不吃掉异常,只感知异常
Use the finally block to clean up resources or a Java 7 “try-with-resource” construct.
无论是流正常结束还是异常结束都会执行doFinally里面的方法
1 2 3 Flux.just("1" ,"2" ,"3" ) .map(this ::myMethod) .doFinally(this ::myMethod)
当异常出现的时候处理异常并继续执行 ,不会中断流的操作
1 2 3 4 5 6 7 Flux.just("1" ,"2" ,"3" ) .map(this ::myMethod) .onErrorContinue((err, value) -> { System.out.println("error = " + err); System.out.println("value = " + value); log.error("发现{}有问题,并继续执行" , value); })
当发生错误的时候从源头中断流
一个流有多个订阅者,如果其中一个使用了onErrorStop之后并且发生异常了,那么其他正常的订阅者也会被停止。
如果不适用该操作,那么其中一个出现错误了,其他的不会被停止
将流错误信号转换成正常结束信号,也会中断流
设置超时时间,如果流在规定的超时时间内无法到达下流,则会异常
timeout
1 2 3 4 5 6 7 8 9 Flux.just(1 ,2 ,3 ) .delayElements(Duration.ofSeconds(3 )) .timeout(Duration.ofSeconds(2 )) .onErrorResume(err -> { System.out.println("超时啦" ); return Mono.empty(); }) .log() .subscribe();
设置重试机制
retry 重试的时候会将流中的元素从头到尾重新请求一遍
1 2 3 4 5 6 Flux.just(1 ,2 ,3 ) .delayElements(Duration.ofSeconds(3 )) .timeout(Duration.ofSeconds(2 )) .retry(3 ) .log() .subscribe();
Sinks 数据管道,所有数据都是顺着这个管道向下走
发送Flux数据
单播,只有一条管道,只能绑定一个消费者
1 2 3 4 5 6 7 8 9 10 11 12 13 Sinks.Many<Object> many = Sinks.many() .unicast() .onBackpressureBuffer(); new Thread (() -> { for (int i = 0 ; i < 10 ; i++) { many.tryEmitNext("a-" +i); } }).start(); many.asFlux().subscribe(System.out::println);
如果上述Sinks创建的对象被多个订阅者订阅的话会报错
默认订阅者是从订阅开始的时候开始接受元素
多播模式可以被多个订阅者订阅
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Sinks.Many<Object> many = Sinks.many() .multicast().onBackpressureBuffer(); new Thread (() -> { for (int i = 0 ; i < 10 ; i++) { many.tryEmitNext("a-" +i); try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } } }).start(); many.asFlux().subscribe(a -> System.out.println("v1-" + a)); many.asFlux().subscribe(a -> System.out.println("v2-" + a));
重放,使用该方法会让管道能够重放,是否给后来的订阅者发送之前发送过的数据 。
底层:用队列存放之前发送过的数据
用来判断订阅者接受订阅之后发送的数据,还是可以接受订阅之前发送的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 Sinks.Many<Object> many = Sinks.many() .replay() .limit(3 ); new Thread (() -> { for (int i = 0 ; i < 10 ; i++) { many.tryEmitNext("a-" +i); try { Thread.sleep(1000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } } }).start(); many.asFlux().subscribe(a -> System.out.println("v1-" + a)); new Thread (() -> { try { Thread.sleep(5000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } many.asFlux().subscribe(a -> System.out.println("v2-" + a)); }).start();
输出结果
从第五秒开始一下订阅之前发过的三个元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 v1-a-0 v1-a-1 v1-a-2 v1-a-3 v1-a-4 v2-a-2 v2-a-3 v2-a-4 v1-a-5 v2-a-5 v1-a-6 v2-a-6 v1-a-7 v2-a-7 v1-a-8 v2-a-8 v1-a-9 v2-a-9
缓存发布的信息,不设置缓存信息,默认缓存所有
1 2 3 4 5 6 7 8 9 10 11 12 13 Flux<Integer> integerFlux = Flux.range(1 , 15 ) .delayElements(Duration.ofSeconds(1 )) .cache(1 ); integerFlux.subscribe(a -> System.out.println("v1-" + a)); new Thread (() -> { try { Thread.sleep(9000 ); } catch (InterruptedException e) { throw new RuntimeException (e); } integerFlux.subscribe(a -> System.out.println("v2-" + a)); }).start();
阻塞,当想要拿到Flux流中的数据的时候可以使用block来获取
1 2 3 4 5 List<Integer> block = Flux.just(1 , 2 , 3 ) .map(i -> i + 10 ) .collectList() .block(); System.out.println(block);
有1000000哥数据,现在想要通过8个线程来处理操作,每个线程处理100个数据,直到
1 2 3 4 5 6 7 List<Integer> block = Flux.range(1 , 1000000 ) .buffer(10 ) .parallel(8 ) .runOn(Schedulers.newParallel("yy" )) .flatMap(Flux::fromIterable) .collectSortedList(Integer::compareTo) .block();
设置上下文操作 ,通过设置COntext中的内容,让上流够拿到下流中的参数,上流能够拿到下流中的最近一次的数据
1 2 3 4 5 6 7 8 Flux.just(1 ,2 ,3 ,4 ) .transformDeferredContextual((flux, context) -> { System.out.println(flux); System.out.println(context); return flux.map(i -> i + "====" + context.get("value" )); }) .contextWrite(Context.of("value" , "haha" )) .subscribe(System.out::println);
因为在响应式编程中,整体的流程有所改变,所以需要通过设置上下文的方式来进行参数的传递
在响应式编程中,先是通过DAO层获取数据,Service层定于DAO层获取的数据,最后Controller层订阅Service处理的数据,最后返回给前端
在这个过程中,DAO作为资源发布者,从数据库中读取数据,最后经过一系列处理操作,返回个前台
以前:浏览器 —> Controller ----> Service —> Dao
现在:DAO ----> Service ----> Controller ----> 浏览器
底层基于Netty+reactor+SpringWeb完成一个全异步非阻塞的web响应式框架
底层:异步 + 消息队列 + 事件回调 = 整套系统
优点:使用少量资源处理大量请求
API功能
Servlet-阻塞式Web
WebFlux-响应式Web
前端控制器
DispatcherServlet
DispatcherHandler
处理器
Controller
WebHandler/Controller
请求/响应
ServletRequest/ServletResponse
ServletWebExchange:ServerRequest/ServerResponse
过滤器
Filter(HttpFilter)
WebFilter
异常处理器
HandlerExceptionResolver
DispatchExceptionHandler
Web配置
@EnableWebMvc
@EnableWebFlux
自定义配置
WebMvcConfigurer
WebFluxConfigurer
返回结果
任意
Mono,Flux,任意
返送Rest请求
RestTemplate
WebClient
1 2 3 4 5 6 7 8 9 10 11 12 <parent > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-parent</artifactId > <version > 3.4.0</version > <relativePath /> </parent > <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-webflux</artifactId > </dependency > </dependencies >
在这个里面,返回值为List类型用Flux返回, 返回值为实体类型的用Mono接受
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @RestController @RequestMapping("/users") public class MyRestController { private final UserRepository userRepository; private final CustomerRepository customerRepository; public MyRestController (UserRepository userRepository, CustomerRepository customerRepository) { this .userRepository = userRepository; this .customerRepository = customerRepository; } @GetMapping("/{userId}") public Mono<User> getUser (@PathVariable Long userId) { return this .userRepository.findById(userId); } @GetMapping("/{userId}/customers") public Flux<Customer> getUserCustomers (@PathVariable Long userId) { return this .userRepository.findById(userId).flatMapMany(this .customerRepository::findByUser); } @DeleteMapping("/{userId}") public Mono<Void> deleteUser (@PathVariable Long userId) { return this .userRepository.deleteById(userId); } }
以前:浏览器 —> Controller ----> Service —> Dao
现在:DAO ----> Service ----> Controller ----> 浏览器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public static void main (String[] args) throws IOException { HttpHandler httpHandler = (serverHttpRequest, serverHttpResponse) -> { URI uri = serverHttpRequest.getURI(); System.out.println(uri); return Mono.empty(); }; ReactorHttpHandlerAdapter adapter = new ReactorHttpHandlerAdapter (httpHandler); HttpServer.create() .host("localhost" ) .port(8080 ) .handle(adapter) .bindNow(); System.in.read(); }
在Webflux开发中SpringBoot中的开放方式基本支持
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @RestController public class HelloController { @GetMapping("/aa") public String aa () { return "aa" ; } @GetMapping("/bb") public Mono<String> bb () { return Mono.just("bb" ); } @GetMapping("cc") public Flux<String> cc () { return Flux.just("c1" , "c2" , "c3" ); } @GetMapping(value = "/sse", produces = MediaType.TEXT_EVENT_STREAM_VALUE) public Flux<String> sse () { return Flux.range(1 ,10 ) .map(i -> "sse-" +i) .delayElements(Duration.ofSeconds(1 )); } }
ServerSendEvent
完整的处理流程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @GetMapping(value = "/sse", produces = MediaType.TEXT_EVENT_STREAM_VALUE) public Flux<ServerSendEvent<String>> sse () { return Flux.range(1 ,10 ) .map(i -> { return ServerSendEvent.builder("ha-" +i) .id(i + "" ) .comment("hei-" +i) .event("haha" ) .build(); }) .delayElements(Duration.ofSeconds(1 )); }
SSE和webSocket的区别:
SSE是单通道,只能后端持续的给前台发送数据
webSocket是多通道,后端可以给前台发送数据,前台也能够给后台发送数据
包含三个处理器
HandlerMapping:请求映射处理器 ,保存每个请求由那个方法进行处理
HandlerAdapter:处理适配器 ,反射执行目标方法
HandlerResultHandler:处理器结果处理器
对比
SpringMVc:DispatcherServlet 有一个 doDispatch() 方法,来处理所有请求;
WebFlux:DispatcherHandler 有一个 handle() 方法,来处理所有请求;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public Mono<Void> handle (ServerWebExchange exchange) { if (this .handlerMappings == null ) { return this .createNotFoundError(); } else { return CorsUtils.isPreFlightRequest(exchange.getRequest()) ? this .handlePreFlight(exchange) : Flux.fromIterable(this .handlerMappings) .concatMap((mapping) -> { return mapping.getHandler(exchange); }) .next() .switchIfEmpty(this .createNotFoundError()) .onErrorResume((ex) -> { return this .handleResultMono(exchange, Mono.error(ex)); }) .flatMap((handler) -> { return this .handleRequestWith(exchange, handler); }); } } private <R> Mono<R> createNotFoundError () { return Mono.defer(() -> { Exception ex = new ResponseStatusException (HttpStatus.NOT_FOUND); return Mono.error(ex); }); } private Mono<Void> handleRequestWith (ServerWebExchange exchange, Object handler) { if (ObjectUtils.nullSafeEquals(exchange.getResponse().getStatusCode(), HttpStatus.FORBIDDEN)) { return Mono.empty(); } else { if (this .handlerAdapters != null ) { Iterator var3 = this .handlerAdapters.iterator(); while (var3.hasNext()) { HandlerAdapter adapter = (HandlerAdapter)var3.next(); if (adapter.supports(handler)) { Mono<HandlerResult> resultMono = adapter.handle(exchange, handler); return this .handleResultMono(exchange, resultMono); } } } return Mono.error(new IllegalStateException ("No HandlerAdapter: " + handler)); } }
所有的请求和相应都封装在ServerWebExchange对象中,通过handle方法进行处理
首先如果没有任何请求映射器,则直接返回错误信息,新建一个错误信息并返回
通过Mono.deffer方式创建一个错误对象,直到流被订阅的时候才会实例化错误对象
如果不适用Mono.deffer方法将操作进行封装,那么在返回Mono.error错误对象的时候,都会新建一个ResponseStatusException对象,这就会导致,流还没有被订阅的时候,错误对象已经创建出来了
通过使用Differ创建的错误流,只有在流由订阅者,并且流被激活的时候才会动态调用此方法,延迟加载
最后通过三元表达式,来判断是否是跨域请求,如果是跨域请求则需要预检查
Flux流式操作,先找到HandlerMapping,在获取handlerMapping,通过调用Adapter处理请求,期间的错误由onErrorResume处理
通过concatMap获取那个Mapping能够处理该请求
通过next获取第一个能处理该请求的handler,如果是空则将流抛出异常,通过异常处理方法处理此异常
如果没有错误则通用handleRequestWith处理此请求
handleRequestWith 和 handlerResult
handleRequestWith:编写了handlerAdapters怎么处理请求
handleResultMono:处理结果
Controller参数
描述
ServerWebExchange封装了请求和相应
ServerHttpRequest, ServerHttpResponse请求和相应
WebSession可以访问Session对象
org.springframework.http.HttpMethod
获取请求方法,post,get
@PathVariable路径参数标注点
@RequestParam请求参数
`@RequestHeader
获取请求头
@CookieValue获取Cookie值
@RequestBody获取请求体中包含的数据
HttpEntity<B>获取请求头和请求体
@RequestPart获取文件上传数据 multipart/from-data
java.util.Map or org.springframework.ui.ModelFor access to the model that is used in HTML controllers and is exposed to templates as part of view rendering.
Errors or BindingResult数据校验
@SessionAttribute获取Session对象
@RequestAttribute获取转发请求
Controller返回值
描述
@ResponseBody将相应的数据写出去,如果是对象则自动转换成JSON
HttpEntity<B>, ResponseEntity<B>支持快捷自定义相应内容
HttpHeaders没有响应体只有相应头
ErrorResponse快速构建错误相应
ProblemDetailTo render an RFC 9457 error response with details in the body, see Error Responses
String返回字符串可以被视图解析器处理
View返回视图对象
Rendering也是一种视图对象
FragmentsRendering, Flux<Fragment>, Collection<Fragment>For rendering one or more fragments each with its own view and model. See HTML Fragments for more details.
void仅代表相应完成
Flux<ServerSentEvent>, Observable<ServerSentEvent>, or other reactive type使用text/event-stream完成SSE效果
1 2 3 4 5 6 7 8 9 10 11 12 @GetMapping("/entity") public ResponseEntity<String> entity () { return ResponseEntity .status(200 ) .contentType(MediaType.TEXT_EVENT_STREAM) .body("hhh" ); } @GetMapping("/baidu") public Rendering baidu () { return Rendering.redirectTo("http://www.baidu.com" ).build(); }
Multipart Content :: Spring Framework
以前
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class MyForm { private String name; private MultipartFile file; } @Controller public class FileUploadController { @PostMapping("/form") public String handleFormUpload (MyForm form, BindingResult errors) { } }
现在:通过Filepart来获取上传文件
1 2 3 4 5 @PostMapping("/") public String handle (@RequestPart("meta-data") Part metadata, @RequestPart("file-data") FilePart file) { }
ErrorResponse
1 2 3 4 5 6 @GetMapping("/error") public ErrorResponse errorResponse () { RuntimeException runtimeException = new RuntimeException (); return ErrorResponse.builder(runtimeException, HttpStatusCode.valueOf(500 ), "hhh" ) .build(); }
通过创建config类,实现WebFluxConfigurer类的自动装配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Configuration public class MyWebFluxConfiguration { @Bean public WebFluxConfigurer webFluxConfigurer () { return new WebFluxConfigurer () { @Override public void addCorsMappings (CorsRegistry registry) { registry.addMapping("/**" ) .allowedOrigins("*" ) .allowedMethods("*" ) .allowedOrigins("localhost" ); } }; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 @Component public class MyWebFilter implements WebFilter { @Override public Mono<Void> filter (ServerWebExchange exchange, WebFilterChain chain) { ServerHttpRequest request = exchange.getRequest(); ServerHttpResponse response = exchange.getResponse(); System.out.println("请求到目标方法执勤啊" ); return chain.filter(exchange) .doFinally(signalType -> System.out.println("请求完目标方法之后" )); } }
R2DBC官网
1 2 3 4 5 6 7 <dependency > <groupId > io.asyncer</groupId > <artifactId > r2dbc-mysql</artifactId > <version > 1.3.1</version > <scope > test</scope > </dependency >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public void myTest () throws IOException { MySqlConnectionConfiguration mySqlConnectionConfiguration = MySqlConnectionConfiguration.builder() .password("admin" ) .username("root" ) .database("db2024" ) .host("127.0.0.1" ) .build(); MySqlConnectionFactory connectionFactory = MySqlConnectionFactory.from(mySqlConnectionConfiguration); Mono.from(connectionFactory.create()) .flatMapMany(connection -> connection.createStatement("select * from security_user where id like ?id" ) .bind("id" , "%1%" ) .execute()) .flatMap(result -> result.map(readable -> { String id = readable.get("id" , String.class); String username = readable.get("username" , String.class); String password = readable.get("password" , String.class); return new User (id, username, password); })) .subscribe(System.out::println); System.in.read(); }
在传统的JDBC中如果我们通过分页查询数据的时候,查询第一页就发送一条SQL,建立一个链接,获取数据,关闭链接
在R2dbc中我们一共建立一个链接,并且不会关闭,通过take获取数据,获取几个数据,数据库就返回几个数据,不用频繁查询,构建连接
1 2 3 4 5 6 7 8 9 10 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-r2dbc</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-webflux</artifactId > </dependency >
R2dbcAutoConfiguration:主要提供了连接工厂,连接池等操作
R2dbcDataAutoConfiguration:主要提供了r2dbcEntityTemplate 可以进行CRUD操作
r2dbcEntityTemplate ,操作数据的响应式客户端,提供CRUD
数据类型映射关系,转换器,自定义r2dbcCustomConversions 转换器组件
数据类型转换:VARCHAR -> String等操作
R2dbcRepositoriesAutoConfiguration:开启Spring Data声明式接口方式CRUD
例如Mybatis-Plus:提供了BaseMapper和IService等,自带了CRUD操作
Spring data:提供了CRUD接口,不用写任何实现类的情况下,可直接具备CRUD操作
QBC:Query By Criteria
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @SpringBootTest public class R2DbcTest { @Autowired private R2dbcEntityTemplate r2dbcEntityTemplate; @Test public void r2dbcEntityTemplate () throws IOException { Criteria criteria = Criteria.empty() .and("id" ).is("1" ); Query query = Query.query(criteria); r2dbcEntityTemplate.select(query, User.class) .subscribe(System.out::println); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @SpringBootTest public class R2DbcTest { @Autowired private DatabaseClient databaseClient; @Test public void databaseClient () throws IOException { databaseClient.sql("select * from security_user" ) .fetch() .all() .map(map -> { System.out.println(map); return new User (); }) .subscribe(System.out::println); System.in.read(); } }
测试-
R2DBC Repositories :: Spring Data Relational
类似Mybatis-Plus中的IService,和BaseMapper
继承了很多CURD实现方法
QBE: Query BY Example
实现配置信息
1 2 3 4 @EnableR2dbcRepositories @Configuration public class R2DbcConfiguration {}
继承R2dbcRepository接口,泛型第一个是该接口的实体类,第二个是该接口的主键类型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Repository public interface UserRepositories extends R2dbcRepository <User, String> { Flux<User> findAllByIdIsAndUserNameLike (String id, String name) ; }
使用接口信息
1 2 3 4 5 6 7 @Test public void userRepositories () throws IOException { userRepositories.findAll() .subscribe(System.out::println); System.in.read(); }
通过给接口命名来查询指定信息,例如下面的信息
1 2 3 4 5 6 7 8 9 Flux<User> findAllByIdIsAndUserNameLike (String id, String name) ;
通过指定SQL查询语句来查询指定信息
1 2 3 4 5 6 @Query("SELECT * FROM security_user") Flux<User> myMethod () ;
现在用户表和图书表,一个图书对应一个作者,一个作者对应多个图书
**一对一:**查询图书的时候将其对应的作者的信息查询出来
定义实体类:在图书对象中封装用户信息
1 2 3 4 5 6 7 8 9 10 11 12 @Data @Table("t_book") public class Book { @Id private String id; private String title; private LocalDateTime createTime; private String authorId; @Transient private User user; }
定义查询方法
1 2 3 4 5 6 7 8 @Repository public interface BookRepositories extends R2dbcRepository <Book, String> { @Query("select b.*, u.USERNAME author_name from t_book b " + " left join security_user u on b.author_id = u.ID " + " where b.id = :bookId") Mono<Book> findBookAndAuthor (@Param("bookId") String bookId) ; }
定义转换器:将查询出来的结果生成book对象并返回
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @ReadingConverter public class BookConverter implements Converter <Row, Book> { @Override public Book convert (Row source) { String id = source.get("id" , String.class); String title = source.get("title" , String.class); LocalDateTime createTime = source.get("create_time" , LocalDateTime.class); String authorId = source.get("author_id" , String.class); String authorName = source.get("author_name" , String.class); Book book = new Book (); book.setId(id); book.setTitle(title); book.setCreateTime(createTime); book.setAuthorId(authorId); User user = new User (); user.setId(id); user.setUserName(authorName); book.setUser(user); return book; } }
注册转换器:在R2DBC配置中设置转换器
1 2 3 4 5 6 7 8 9 10 @EnableR2dbcRepositories @Configuration public class R2DbcConfiguration { @Bean @ConditionalOnMissingBean public R2dbcCustomConversions r2dbcCustomConversions () { return R2dbcCustomConversions.of(MySqlDialect.INSTANCE, new BookConverter ()); } }
查询操作:直接查询出图书及其作者信息
1 2 3 4 5 6 7 @Test public void userRepositories () throws IOException { bookRepositories.findBookAndAuthor("1" ) .subscribe(System.out::println); System.in.read(); }
SpringData 在发现方法签名返回值是Book对象的时候就会调用自己设置BookConverter将返回值封装成Book对象
**缺陷:如果设置了转化器,那么Repository中的所有返回类型是Book的方法都会去用这个转换器进行转换,在转换器中设置了 String authorId = source.get(“author_id”, String.class);**这个方式去获取作者的id和姓名,在使用简单查询的时候,例如findbyId的时候,返回值结果中没有author_id这一项,会导致转换器报错,
解决方法:
设置新Vo类 + 新Respository + 新映射类进行结果映射
在转换器中进行校验,**source.getMetadata().contains(“author_name”)**来判断返回结果是否有这一列,如果有再进行结果映射
**一对多:**通过查出作者及其所有图书信息
结果信息:
**方式一:**通过使用groupby 将user_id分组,user_id一样的分为同一组,可以乱序
**方式二:**使用BufferUntilChange来进行分组,将符合条件的分为同一组,必须按照user_id排好序 ,否则分不到一组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 List<User> block = databaseClient.sql("SELECT a.id user_id, a.USERNAME username , b.* FROM security_user a" + " LEFT JOIN t_book b ON a.ID = b.author_id" ) .fetch() .all() .bufferUntilChanged(rowMap -> Long.parseLong(rowMap.get("user_id" ).toString())) .map(bookList -> { Map<String, Object> first = bookList.get(0 ); User user = new User (); user.setId(first.get("user_id" ).toString()); user.setUserName(first.get("username" ).toString()); List<Book> list = bookList.stream() .map(book -> { if (book.get("id" ) == null || StringUtils.isBlank(book.get("id" ).toString())) return null ; Book tempBook = new Book (); tempBook.setId(book.get("id" ).toString()); tempBook.setTitle(book.get("title" ).toString()); tempBook.setAuthorId(book.get("author_id" ).toString()); return tempBook; }) .filter(Objects::nonNull) .toList(); user.setBooks(list); return user; }) .collectList() .block(); System.out.println(block);
Spring Data R2DBC,基础的CRUD 用R2dbcRepository提供好了
自定义复杂的SOL(单表):@Query查询; 无需要做结果映射的
多表查询复杂结果集:
DataBaseClient 自定义SQL及结果封装
@Query注解 + 自定义Converter 实现对结果集封装
依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 <dependencies > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-test</artifactId > <scope > test</scope > </dependency > <dependency > <groupId > io.asyncer</groupId > <artifactId > r2dbc-mysql</artifactId > </dependency > <dependency > <groupId > org.projectlombok</groupId > <artifactId > lombok</artifactId > <scope > provided</scope > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-r2dbc</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-webflux</artifactId > </dependency > <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-security</artifactId > </dependency > </dependencies >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @Configuration @EnableReactiveMethodSecurity @RequiredArgsConstructor(onConstructor = @__(@Autowired)) public class AppSecurityConfiguration { @Lazy @Resource private AppReactiveUserDetailsService userDetailsService; @Bean SecurityWebFilterChain springSecurityFilterChain (ServerHttpSecurity http) { http.authorizeExchange(authorize -> { authorize.matchers(PathRequest.toStaticResources().atCommonLocations()).permitAll(); authorize.anyExchange().authenticated(); }); http.formLogin(); http.csrf(ServerHttpSecurity.CsrfSpec::disable); http.authenticationManager(new UserDetailsRepositoryReactiveAuthenticationManager (userDetailsService)); return http.build(); } @Bean PasswordEncoder passwordEncoder () { return PasswordEncoderFactories.createDelegatingPasswordEncoder(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Component @RequiredArgsConstructor(onConstructor = @__(@Autowired)) public class AppReactiveUserDetailsService implements ReactiveUserDetailsService { private final DatabaseClient databaseClient; @Resource @Lazy private PasswordEncoder passwordEncoder; @Override public Mono<UserDetails> findByUsername (String username) { return databaseClient.sql("SELECT u.*, r.`name` r_name, r.id rid, r.`value` r_value, p.id pid, p.`value` p_value, p.description p_description FROM t_user u\n" + "LEFT JOIN t_user_role ur ON ur.user_id = u.id\n" + "LEFT JOIN t_roles r ON r.id = ur.role_id\n" + "LEFT JOIN t_role_perm rp ON rp.role_id = r.id\n" + "LEFT JOIN t_perm p ON p.id = rp.perm_id " + "WHERE u.username = ?username " + "ORDER BY u.id DESC" ) .bind(0 , username) .fetch() .all() .bufferUntilChanged(row -> row.get("id" )) .map(rows -> { Map<String, Object> stringObjectMap = rows.get(0 ); HashSet<String> roelNameSet = new HashSet <>(); HashSet<String> permNameSet = new HashSet <>(); rows.forEach(row -> { roelNameSet.add(row.get("r_name" ).toString()); permNameSet.add(row.get("p_value" ).toString()); }); return User.builder() .username(stringObjectMap.get("username" ).toString()) .password(stringObjectMap.get("password" ).toString()) .roles(roelNameSet.toArray(new String [0 ])) .build(); }) .next(); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @RestController public class HelloController { @PreAuthorize("hasRole('admin')") @GetMapping("/hello") public Mono<String> hello () { return Mono.just("Hello" ); } @PreAuthorize("hasAuthority('view')") @GetMapping("/haha") public Mono<String> haha () { return Mono.just("Haha" ); } }